March 2025
Initial overview
Dating back to March 2024, we announced that we'd be bringing the functionality of creating courses from any PDF document to our community.
In the first couple of weeks of our release, our users had high satisfaction with their courses — we received feedback that it was now relieving for them to create their course with an Artificial Intelligence (AI) tool as they could now rapidly use their resources while having a clear expectation on the accuracy of their outputs.
Yet, our users also did not shy away to point out when they started encountering problems. We received messages that there was some odd and unhelpful content in the created courses — lengthy sentences along with the deviations in the accuracy of the generated information. As we hold ourselves to high standards of accountability, we appreciated the feedback and took it seriously. And now, we want to share a clear sense of what happened, why it matters, and the steps we've taken.
Generative AI landscape and Mini-Course Generator
For the past couple of years, we have witnessed that big companies such as OpenAI, Meta, Google, and Anthropic have been leading the rapid developments regarding Generative AI (Gen AI), making the generation of multi-modal outputs, such as text, images, and audio to be notably accessible across various domains, spanning from education to entertainment. Similar to hundreds of other applications, we envisioned a near future where educational content creators can efficiently create resources by leveraging these technologies. With that naive road in mind, we started with a feature powered by established large language model (LLM) APIs as the sole knowledge source for the course creation. Along the way, our community's voice highlighted that creating a course from their own resources would be beneficial, for which we utilized that day's highest standard framework, namely, Retrieval Augmented Generation (RAG) system. While RAG systems were specifically designed to ground LLMs' responses to a specialized external information source, ensuring its outputs to be more accurate and eventually trusted, we discovered that even these systems were not immune to the growing challenge of the 'hallucinating' incorrect or implausible information.
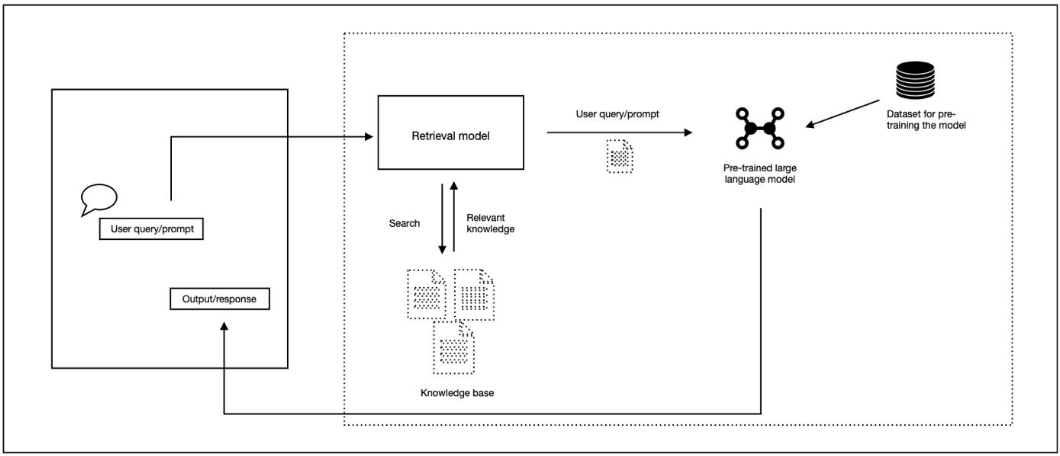
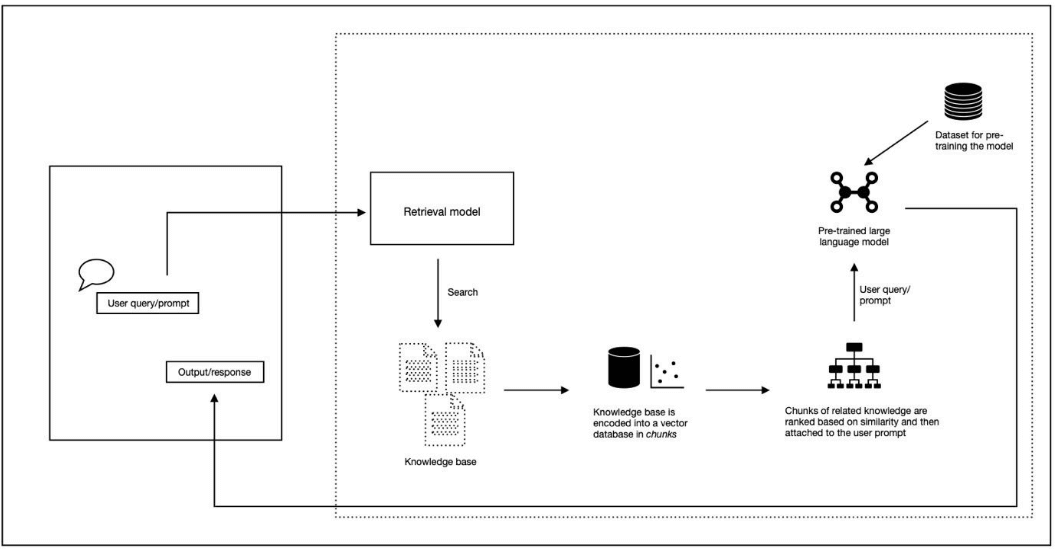
To be more specific, in our implementation, we encountered several significant technical challenges that highlighted the limitations of our RAG pipeline, typically due to the steps in between the retrieval and augmentation:
- Vector database retrieval problems: Our initial experiments revealed significant challenges in the foundational retrieval phase, where the vector database consistently failed to retrieve contextually appropriate texts. The semantic similarity scores were not reliably identifying the most relevant content, forcing the system to work with incomplete or inappropriate context, which significantly increased the risk of hallucinations.
- Semantic relationship limitations: The root cause of these retrieval problems became clear as we discovered that relying on numerical representations (i.e., vectors) for semantic understanding was insufficient for capturing nuanced conceptual relationships, leading to misinterpretations and incorrect inferences.
- Re-ranking issues: Our re-ranking mechanisms proved inadequate in properly weighing and prioritizing relevant content. This resulted in information dilution, where marginally relevant content got prioritized over more pertinent information, ultimately affecting the quality of generated responses.

Given these challenges in implementing RAG in learning material generation, we decided to adopt a more pragmatic approach, focusing on title-based associations along with a consistency checker step that could better constrain potential extrinsic hallucinations.
Evaluating factual consistency: An approach to managing hallucinations
Having identified the limitations of the RAG system, we next focused on an additional method for managing hallucinations. Although perfect fact-checking would require deep semantic understanding, we determined that quantifying the alignment between generated text and its source could provide a proxy for factual consistency, leading us to implement a systematic text comparison approach that converts textual information into numerical representations and generates a factual consistency score.
Our solution implemented this approach through three key steps:
- Text cleaning, which removes stop-words and formatting inconsistencies to focus the comparison on content-carrying terms.
- Semantic encoding, which employs spaCy's language model to transform the cleaned text into numerical representations for a mathematical comparison.
- Similarity assessment, which applies cosine similarity calculations (a score between 0 and 1, where 1 indicates perfect similarity) to quantify the alignment between source and generated content.
As an illustrative example, consider a source text about the Renaissance period and its AI-generated explanation (see Figure 4). The method can recognize semantic alignment despite variations in phrasing while still identifying potential factual inconsistencies.

Improvements and ongoing challenges
Building on this approach, we designed a testing strategy examining both typical educational content and intentionally challenging edge cases. While we can speculate about how users might interact with this combined approach, we recognize that real-world implementation will provide the true test of our solution's value in managing hallucinations.
To provide evidence of our integrated approach's effectiveness, we compiled a snippet of initial test results showing similarity scores across different types of source materials and their corresponding AI-generated course versions in Table 1.
| Original source (pdf version) | Course link | Consistency Score (0–1) |
|---|---|---|
| Libre Office | Basics of Libre Office | 0.9827 |
| Aspirin Instructions | Aspirin's Instructions for Use | 0.9886 |
| Stories from the Bible | Ten Stories from the Bible | 0.9361 |
| Residency Guide | E-Residency Guide | 0.9882 |
| World Economic Outlook | World Economic Outlook Update on Global Growth | 0.9891 |
Table 1. The approach demonstrates potential across diverse content types. However, we are cognizant that while this method provides a quick, automated way to compare texts for factual consistency, it does not truly understand facts — it measures semantic similarity, meaning it can detect shifts in wording but may still miss deeper inaccuracies or subtle misinformation.
Though our proposed integrated solution won't completely eliminate inconsistencies, initial testing results suggest it offers a feasible and measurable step forward in identifying factual consistencies in generated texts and their original sources.
Wrap up
As Mini Course Generator, we have taken systematic steps to address the challenge of hallucinations in AI-generated educational content. Our journey evolved from a traditional RAG system to a more focused approach combining title-based associations with a quantitative consistency checking mechanism.
While our initial test results demonstrate measurable improvements in content accuracy, we acknowledge that this represents only the beginning of our efforts. As we continue developing our methods, we value constructive feedback that helps improve both our technical implementation and our accountability to the educational communities we learn and grow with.
References
- Anthropic. (2025, February 24). Claude 3.7 Sonnet. anthropic.com
- Banerjee, S., Agarwal, A., & Singla, S. (2024). LLMs will always hallucinate, and we need to live with this. arXiv preprint arXiv:2409.05746.
- Explosion AI. (n.d.). spaCy: Industrial-strength Natural Language Processing in Python. spacy.io
- Google. (2024, December 11). Gemini 2.0. blog.google
- Huang, L., Yu, W., Ma, W., et al. (2025). A survey on hallucination in large language models. ACM Transactions on Information Systems, 43(2), 1-55.
- Lewis, P., Perez, E., Piktus, A., et al. (2021). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
- Martineau, K. (2023, August 22). What is retrieval-augmented generation? IBM Research Blog.
- Mendelevitch, O., Bao, F., Li, M., & Luo, R. (2024, August 5). HHEM 2.1: A better hallucination detection model. Vectara.
- Meta. (2024, April 18). Llama 3. ai.meta.com
- Nicola, J. (2025, January 21). AI hallucinations can't be stopped — but these techniques can limit them. Nature.
- OpenAI. (2024, May 13). GPT-4o. openai.com
- Statista Research Department. (2024, November 12). AI software total product count in 2024. Statista.